增量处理引擎

上图是简化过的增量梳理引擎的拓扑,指向关系代表数据的依赖关系。总体逻辑是ovn-controller根据南向数据库和本机ovsdb中的数据生成ovs的物理流表。
lflow_output负责翻译南向数据库中的逻辑流表,pflow_output负责处理本机端口到逻辑端口的映射关系。具体地,lflow生成物理流表8-32、40-49、66-67,pflow生成物理流表0、37、38、39、64、65。每张物理流表的具体功能见「流表结构」。
物理流表
寄存器
物理流表处理时通过设置寄存器以标识数据包的相关信息。寄存器作用范围仅限当前chassis,当需要跨chassis传输时,会将部分寄存器信息封装到数据包中,具体见「流表规则」中的物理流表37。
| 寄存器 | 含义 |
|---|---|
| metadata | 逻辑数据路径,值为 sbdb 中 datapath 的 tunnel_key |
| reg15 | 逻辑输入端口,值为 sbdb 中 port_binding 的 tunnel_key |
| reg14 | 逻辑输出端口,值为 sbdb 中 port_binding 的 tunnel_key |
| reg13 | conntrack dnat zone |
| reg12 | conntrack snat zone |
| reg11 | logical conntrack zone |
| reg10 | 数据包标志位,值为 ovn/logical-fields.h 中的 enum mff_log_flags |
流表结构
| 物理流表编号 | 功能 |
|---|---|
| 0 | 配置逻辑端口寄存器 |
| 8-32 | 与逻辑流表 ingress pipeline 对应 |
| 37 | 发送输出端口在其他 chassis 的包 |
| 38 | 处理输出端口在本 chassis 包的 ct(连接跟踪)信息 |
| 39 | 丢弃 loopback 包 |
| 40-49 | 与逻辑流表 egress pipeline 对应 |
| 64 | 保存 loopback 包的输入端 |
| 65 | 根据逻辑端口寄存器将数据包发送 |
| 66 | 逻辑路由器处理 IP 与 MAC 的绑定关系 |
| 67 | 逻辑路由器处理 ARP 的 MAC 查询 |
流表规则
下文展示了数据包在三层转发时所使用的具体流表规则。
逻辑拓扑
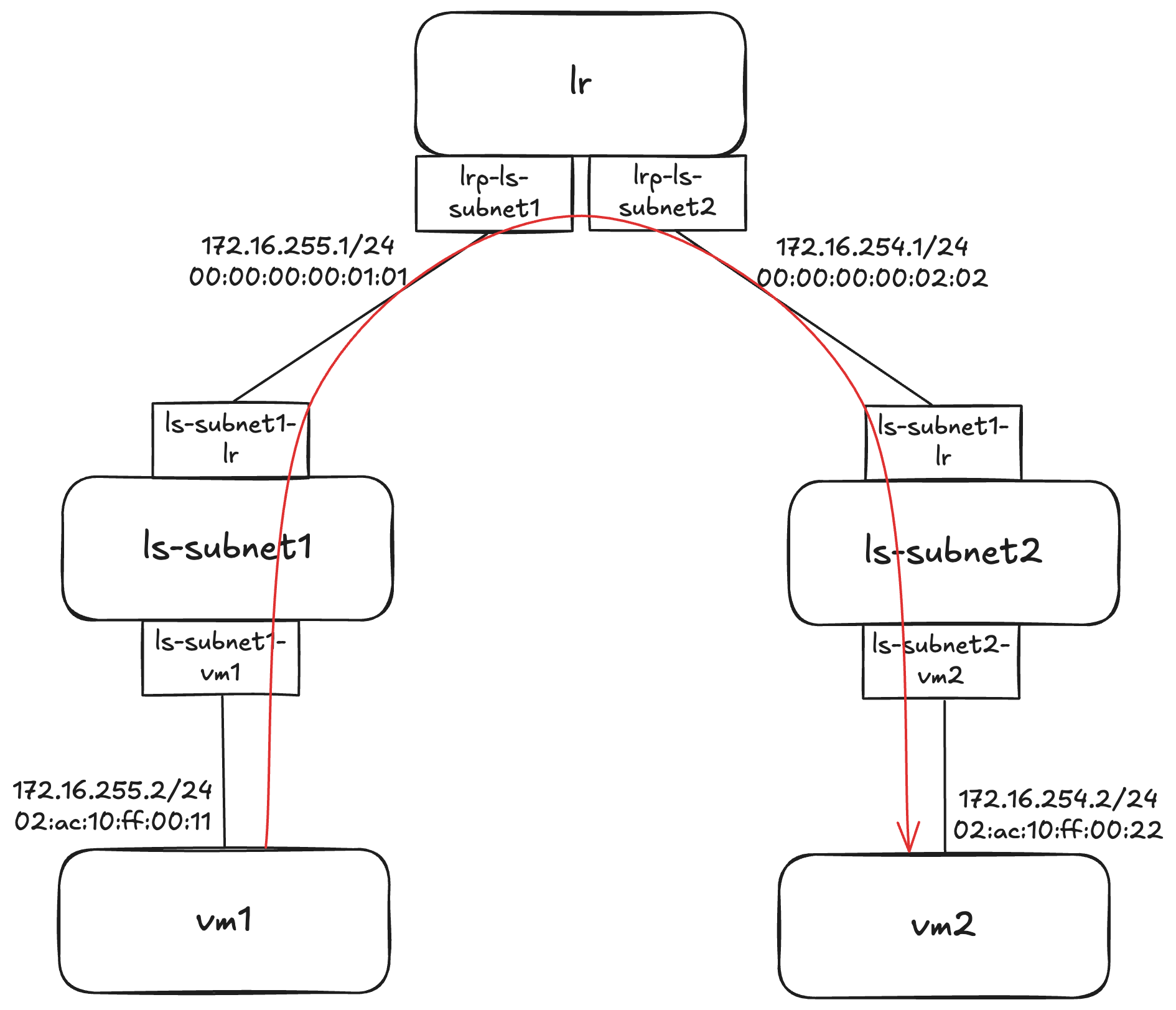
红线代表数据包的逻辑路径,从vm1发出,经过逻辑交换机和逻辑路由器后最终送达vm2。
vm1和vm2分别在不同的chassis上。下文主要观察vm1所在chassis的物理流表,「本机」也指代vm1所在的chassis。
总体流程
数据包从ls-subnet1的datapath发出,经过table0 -> table8-32 -> table38 -> table 40-49 -> table65,最后在table65将数据包发给lrp-ls-subnet1,并将datapath修改为lr。
lr的datapath仍由本机处理,数据包再次经过 table8-32 -> table38 -> table 40-49 -> table65,最后在table65将数据包发给ls-subnet2-lr,并将datapath修改为ls-subnet2。
ls-subnet2的datapth中ingress pipline仍在本机处理,数据包经过 table8-32 -> table37,最后在table37将数据包转发给ls-subnet2所在的chassis。ls-subnet2的chassis只处理egress pipline,数据包经过table0 -> table38 -> table 40-49 -> table65,最后被接收。
物理流表0
1 | priority=100,in_port="ovn-b1d4d7-0" actions=move:NXM_NX_TUN_ID[0..23]->OXM_OF_METADATA[0..23],move:NXM_NX_TUN_METADATA0[16..30]->NXM_NX_REG14[0..14],move:NXM_NX_TUN_METADATA0[0..15]->NXM_NX_REG15[0..15],resubmit(,38) |
第一条规则处理来自ovn-b1d4d7-0的数据包,配置datapath、input port、output port三个寄存器。从其他chassis来的数据包已被ingress pipeline处理且output port已知,因此直接转到table38。
第二条规则处理来自本地的数据包,配置ct、datapath、input port寄存器。本机datapath和input port的值均为0x1。
我们要分析的数据包会从本机的vm1端口送入,匹配到第二条规则,转到table8-32进行ingress pipeline的处理,其中二层转发的逻辑在table32。
物理流表321
2
3table=32, priority=70,metadata=0x1,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=load:0x8000->NXM_NX_REG15[],resubmit(,37)
table=32, priority=50,metadata=0x1,dl_dst=02:ac:10:ff:00:11 actions=load:0x1->NXM_NX_REG15[],resubmit(,37)
table=32, priority=50,metadata=0x1,dl_dst=00:00:00:00:01:01 actions=load:0x2->NXM_NX_REG15[],resubmit(,37)
物理流表只根据目的mac地址配置逻辑输出端口的寄存器,output逻辑会转发到表37和38执行。其中跨chassis转发表37负责,本地转发表38负责。
物理流表381
2
3
4table=38, priority=100,reg15=0x1,metadata=0x1 actions=load:0x5->NXM_NX_REG13[],load:0x7->NXM_NX_REG11[],load:0x4->NXM_NX_REG12[],resubmit(,39)
table=38, priority=100,reg15=0x2,metadata=0x1 actions=load:0x7->NXM_NX_REG11[],load:0x4->NXM_NX_REG12[],resubmit(,39)
table=38, priority=100,reg15=0x8000,metadata=0x1 actions=load:0x5->NXM_NX_REG13[],load:0x1->NXM_NX_REG15[],resubmit(,39),load:0x8000->NXM_NX_REG15[]
table=38, priority=100,reg15=0x1,metadata=0x2 actions=load:0x2->NXM_NX_REG11[],load:0x1->NXM_NX_REG12[],resubmit(,39)
物理流表38主要处理ct逻辑。要分析的数据包随后会转到table40-49进行egress pipeline的处理。egress pipeline的逻辑主要是acl、ct等,跟转发关系不大,因此直接看物理流表65。
物理流表651
2table=65, priority=100,reg15=0x1,metadata=0x1 actions=output:vm1
table=65, priority=100,reg15=0x2,metadata=0x1 actions=clone(ct_clear,load:0->NXM_NX_REG11[],load:0->NXM_NX_REG12[],load:0->NXM_NX_REG13[],load:0x2->NXM_NX_REG11[],load:0x1->NXM_NX_REG12[],load:0x2->OXM_OF_METADATA[],load:0x1->NXM_NX_REG14[],load:0->NXM_NX_REG10[],load:0->NXM_NX_REG15[],load:0->NXM_NX_REG0[],load:0->NXM_NX_REG1[],load:0->NXM_NX_REG2[],load:0->NXM_NX_REG3[],load:0->NXM_NX_REG4[],load:0->NXM_NX_REG5[],load:0->NXM_NX_REG6[],load:0->NXM_NX_REG7[],load:0->NXM_NX_REG8[],load:0->NXM_NX_REG9[],resubmit(,8))
数据包会匹配第二条规则,将metadata配置为数据路径lr对应的0x2,reg14配置为源端口lrp-ls-subnet1对应的0x1,并转发到table8,再次进入ingress pipeline。
由此数据包到进入逻辑路由器进行三层转发,ingress pipeline中路由查询对应的是物理流表19。
物理流表19
1 | table=19,priority=10450,ip,metadata=0x2,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00, nw_dst=224.0.0.0/4 actions=drop |
在物理流表19中会根据目的ip地址设置目的端口和源mac地址。要分析的数据包会匹配第三条规则,将目的端口设置为lrp-ls-subnet2。
随后数据包又送给物理流表32,查询逻辑输出端口。然后经过逻辑路由器lr的egress pipeline,最后到物理流表65,将数据路径改为ls-subnet2,将源端口改为ls-subnet2-lr,并再次送回table8。
由此数据包最终进入ls-subnet2的逻辑。ls-subnet2的ingress pipeline仍在本机的table8-32处理,随后进入table37将数据包转给其他chassis。
物理流表371
2table=37, priority=100,reg15=0x4,metadata=0x3 actions=load:0x3->NXM_NX_TUN_ID[0..23],set_field:0x4->tun_metadata0,move:NXM_NX_REG14[0..14]->NXM_NX_TUN_METADATA0[16..30],output:"ovn-b1d4d7-0",resubmit(,38)
table=37, priority=100,reg15=0x8000,metadata=0x3 actions=load:0x3->NXM_NX_REG15[],resubmit(,39),load:0x8000->NXM_NX_REG15[],load:0x3->NXM_NX_TUN_ID[0..23],set_field:0x8000->tun_metadata0,move:NXM_NX_REG14[0..14]->NXM_NX_TUN_METADATA0[16..30],output:"ovn-b1d4d7-0"
table37中会根据目的端口和数据路径确定目的chassis,其中第一条规则对应单播,第二条规则对应广播。要分析的数据包会匹配第一条规则,送给ovn-b1d4d7-0转到目标chassis上。
在目标chassis上会根据table0的规则直接送到table38,最终经过table40-49 -> table65并收包。
参考资料
https://www.ovn.org/support/dist-docs/ovn-architecture.7.html
https://blog.csdn.net/fengcai_ke/article/details/125710004